 Tweet
Tweet
After almost 2 years of development we are really pleased to make available the V6 beta release for public testing. [Update, 17/Dec/2008: We are out of beta testing and the final V6 release is now available]
This major new release has dozens of new features and 100's of smaller changes. A large proportion of which were implemented as a result of user feedback from the user community. We estimate that there are now over 100,000 web sites and CD's using Zoom Search.
We are really proud of this new release, working on it has been like creating a work of art and we sincerely hope you'll enjoy using it as much as we enjoyed creating it.
Here is a summary of the major new features,
This major new release has dozens of new features and 100's of smaller changes. A large proportion of which were implemented as a result of user feedback from the user community. We estimate that there are now over 100,000 web sites and CD's using Zoom Search.
We are really proud of this new release, working on it has been like creating a work of art and we sincerely hope you'll enjoy using it as much as we enjoyed creating it.
Here is a summary of the major new features,
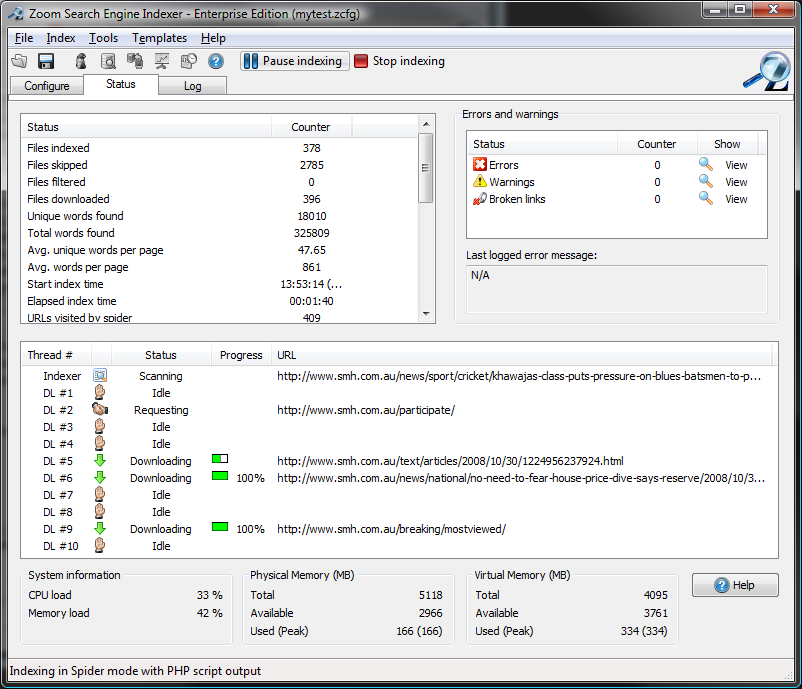
- New User Interface: We have given the UI a complete overhaul and in its place is what we hope is a more intuitive and flexible design. Here are some screenshots of the new interface. It also gives us much more space to add in new configuration options.
- Log window with real-time filtering: You can now filter index log messages on the fly which should be helpful when tracking down error messages, skip reasons, and broken links.
- New Search Ranking Algorithm: The ranking algorithm and index structure have gone through some major improvements. This should produce much more relevant results than before and also allow you greater control of your search results. This includes preference given to words that are found closer together on the same page, and more.
- Faster and more accurate exact phrase searches: There can be an improvement from at least 5% to 60% in search time for exact phrase matches depending on the query and content. You can also now perform exact phrase matching on synonyms, accent insensitive words and stem-matched words (see stemming below).
- Stemming: This allows searches to match words which are similar or derivatives of each other. This addresses an often requested feature to match plural form of words to their singular forms. When this feature is enabled, a search for the word "boat" will match "boats" and "boating". More details on stemming here.
- ASP.NET Server Control: V6 will feature a native ASP.NET platform option. This provides performance similar to the CGI version and is best suited to integrating with ASP.NET web sites.
- Improved highlighting in context descriptions: The highlighting in context descriptions has been improved such that words matching due to stemming, synonyms, or accent insensitivity options enabled can be highlighted.
- Office 2007 plugin: You can now index and search Office 2007 file formats (e.g. DOCX, PPTX, XLSX)
- Improved Vista support: V6 is designed with Vista in mind, and features better compatibility with UAC (User Access Control, folder permissions, etc.). Note that we fully support Vista in the existing V5 of the software, but these V6 changes remove a few Vista quirks.
- Advanced Template options: While your existing search templates from V5 will work in V6, we now also support advanced options so you can customize the appearance of your search results without having to modify the scripting. This includes the ability to repeat or omit certain elements (such as the "Results: 1 2 3 ... " links)
- Custom Meta Fields: Specify arbitrary meta fields to be indexed and made search-able. For example, index and search on a real estate website, by "Number of bedrooms", "Suburb", "Price", "Property type", etc. This is a big feature as it effectively means you can build simple custom databases with a multi criteria search using Zoom without actually having a database. See the Fruits-R-Us demo site for an example of this in action.
- User-specifiable file types: You can specify how each file extension will be handled. For example, you can specify that a .JPZ file be treated as a jpeg file.
- New and improved "Jump to highlighting" script which will be more compatible with other scripts and also exclude highlighting within ZOOMSTOP sections. This can be used to avoid highlighting some sections of your page like the navigation menu.
- MHT plugin for indexing Internet Explorer's MHT web pages.
- Support for optional ZOOMTITLE and ZOOMDESCRIPTION to allow each web page to have a custom meta data that is used only by Zoom, but not by other search engines, like Google. This is useful for SEO work where you need to optimise pages in different ways for different engines.
- Configurable truncate title length option for super long page titles.
- Support for <!--ZOOM_SHOW_QUERY--> tag to insert the search terms into the title of the search results page (or elsewhere on the page)
- Option to "Open all plugin file formats in a new window" so that you can have HTML files open in the same window, and PDF files open in a new window. At the moment in V5 all documents open in the same window, or they all open in a new window.
- Spider image maps. The Zoom spider will now crawl image map links.
- New spider option: FOLLOW_ALL (follow all pages to one level for a start point without indexing the start page).
- Boosting/weighting of each start point. So you can boost/deboost entire domains.
- Thumbnail/images for Recommended Links.
- Checks for changes made to configuration, and prompts user to save config before quitting if changes have been made. This helps avoid accidentally loosing changes.
- Check Thumbnail Exists: Option to check that a thumbnail image exists on the web server before using the link. This means avoid broken links to images that don't exist.
- New, improved method of CRC duplicate page detection: the CRC comparison is now made after stripping out HTML and ZOOMSTOP sections. This means that a page with ads excluded using ZOOMSTOP will now be recognized as being duplicate, despite having different dynamic ads on the page.
- Improved link finding methods in Spider Mode: crawl more pages. In particular there is now more chance that non HTML links that are within Javascript script tags are picked up by the spider. We would still suggest using normal HTML links on your pages where possible however.
- Zoom will now reload the last ZCFG configuration file used by default.
- New PDF scanning method ("Scan text by text layer") to allow for more flexibility when indexing some PDF layouts.
- Toggle option to switch behaviour of accent/diacritic insensitivity to use digraphs or otherwise (i.e. "�" = "oe", etc.)
- Improved compatibility and tolerance of antivirus software and the Windows Indexing Service. Zoom will now deal with cases where the Windows Indexing Service or other 3rd party software (like Antivirus software) is locking Zoom's files.
Comment